Utility-based Adaptive Teaching Strategies using Bayesian Theory of Mind
Good teachers always tailor their explanations to the learners. Cognitive scientists model this process under the rationality principle:
teachers try to maximise the learner's utility while minimising teaching costs. To this end, human teachers seem to build mental models
of the learner's internal state, a capacity known as Theory of Mind (ToM). Inspired by cognitive science, we build on Bayesian ToM mechanisms
to design machine teachers that, like humans, tailor their teaching strategies to the learners. Our ToM-equipped teachers construct models of
learners' internal states from observations and leverage them to select demonstrations that maximise the learners' rewards while minimising teaching costs.
Our experiments in simulated environments demonstrate that learners taught this way are more efficient than those taught in a learner-agnostic way.
This effect gets stronger when the teacher's model of the learner better aligns with the actual learner's state, either using a more accurate prior or
after accumulating observations of the learner's behaviour. This work is a first step towards social machines that teach us and each other.
The source code for this work can be found in this GitHub repository.
We introduce teacher agents that are
endowed with a Theory of Mind (ToM) model of the learner's
internal state, including its goal and receptive field size.
These teacher agents leverage past observations of the learner's behaviour
to tailor their demonstrations to suit the specific observed learner.
The learner needs to open a door of colour defined by its goal,
in the minimum amount of time. It can only see part of its surroundings
through a limited field of view. The goal and the size of the receptive
field can vary among different learners.
The teacher needs to help the learner achieve its goal by providing it a demonstration.
Longer demonstrations are costlier, so the teacher must strike a balance between
ensuring the learner's success while minimizing the cost. goal
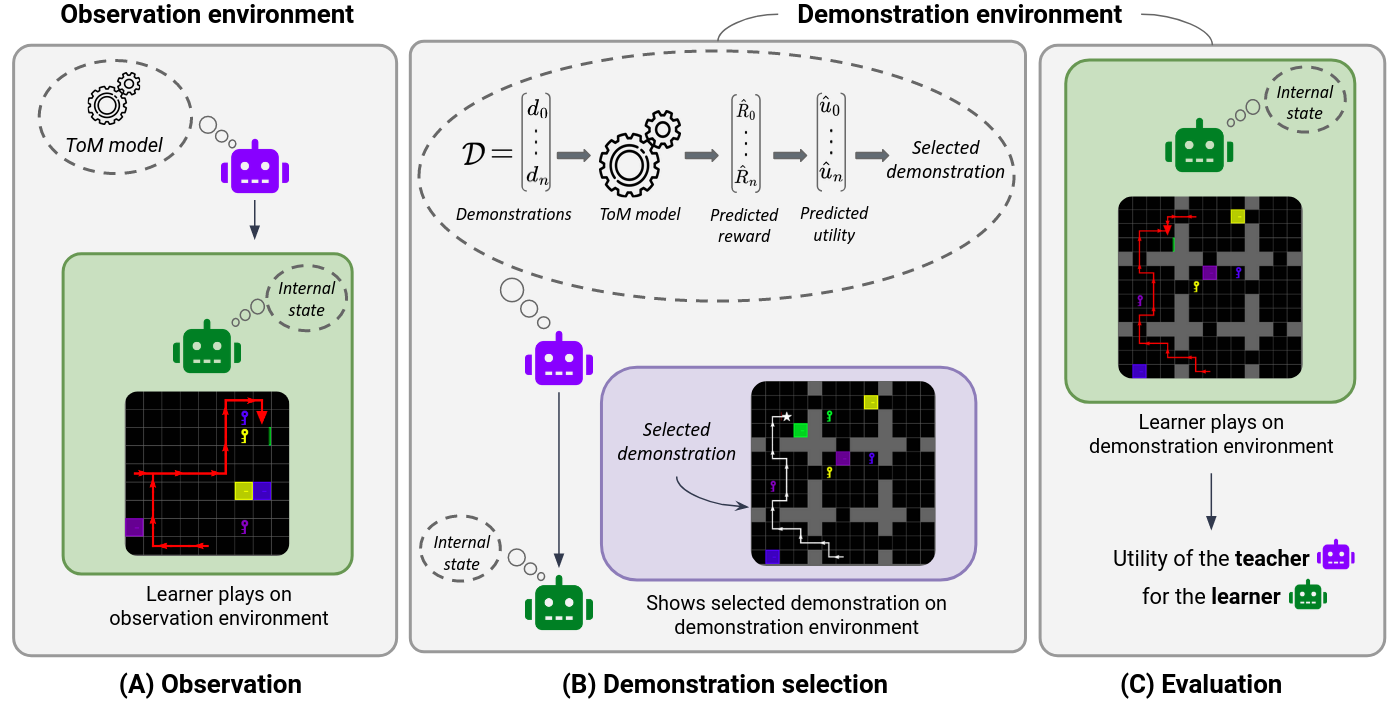
The general framework consists of two environments from Minigrid library: an easy-to-solve observation environment and a more complex demonstration environment where some learners, without assistance, cannot achieve their goals.
The teacher observes the learner in a simple environment and updates its Bayesian ToM
model (i.e., probability map) of the learner's internal state, including the learner's goal and receptive field.
From its final belief, the teacher predicts the reward that the learner would receive after observing demonstrations from a provided dataset.
The teacher selects the demonstration maximising the estimated utility that is the estimated reward of the learner minus the teaching cost of the demonstrations.
The learner observes the demonstration selected by the teacher and acquires new information about the complex environment.
After observing the demonstration selected by the teacher, the learner behaves in the complex environment and receives a reward.
The teacher's evaluation is based on the actual utility of the selected demonstration, which is calculated as the learner's reward
minus the cost of providing the chosen demonstration.
In our paper, we compare the utility of demonstrations selected by ToM-teachers with demonstrations selected
by teachers who use learner-agnostic approaches. Learner-agnostic teachers do not leverage the observations of the learner's
behaviour in the simple environment to tailor their demonstration selections to the specific observed learner. We also
investigate the limits of ToM-teachers' ability to recover the actual learner's internal state, either due to inaccurate priors
about the learner's behavioural policy or limited observation of the learner's
behaviour in the simple environment.